NDLは(デジタル)コンテンツの専門機関
現行の国立国会図書館法(NDL法)の納本制度に関わる条項は次のスライドのとおりである。まず,古くからある納本制度は,同法の24条(国の機関),24条の2(地方公共団体の機関),25条(それ以外の者)によって当該の機関や者は,24条1項に列挙されている「出版物」を発行したら納入する義務がある。見てのとおり,図書から始まって多様な種類の資料が出版物として掲げられている。映画フィルムや蓄音機用レコードなどのオールドメディアがここに含まれている。第8号までは1948年にこの法律ができたときから対象になっていたものであり,第9号はいわゆるパッケージ系の電子出版物の納入規定で2000年から付け加わった。それに対して,同法25条の3により,国の機関および地方公共団体の機関のインターネット資料の収集が可能になっている。インターネット資料とはインターネットで公衆に利用可能な文字,音声,映像,プログラムとされている。通常は自動的な収集ソフトウェアによって取得される。民間のネットワーク系電子出版物(オンライン資料)も収集が可能になっている。

NDLが資料を閲覧に供したり,デジタル化して送信したりするには,著作権を制限する必要があるので,著作権法との関係も深い。とくに,インターネット資料やオンライン資料の収集はここ15年ほどのことであるが,これらを実施するためにはNDL法だけでなく,著作権法の改正も伴っていたので,その当たりについて見ておきたい。(法律の条項は現行のもの)
・2009年(平成21年)著作権法改正ーNDLでの資料の滅失を防いだり,絶版資料のデジタル送信するために資料のデジタル化を可能にした(著作権法31条6項)
・2009年(平成21年) NDL法,著作権法改正ーNDLが国,地方公共団体,独立行政法人等の提供するインターネット資料の収集を可能にした(NDL法25条の3,著作権法43条ほか)
・2012年(平成24年)著作権法改正ーNDL法21年改正で認められたデジタル化された資料の一部(オンライン資料)を図書館に対して公衆送信を可能にした。(著作権法31条7項)
・2021年(令和3年)著作権法改正ー国立国会図書館によるオンライン資料の登録利用者への送信(31条8項〜同条11項)
これらの措置は,国のデジタルトランスフォーメーション政策の一環にも位置付けられていたことが重要である。アメリカの著作権法においては,フェアユース(一定の条件の下で権利者の許諾なしに著作物使用が可能になるという考え方)の存在を前提にしていたことで,ICTの技術開発がしやすかったとされる。日本でも,「権利制限の一般規定(日本版フェアユース規定))が検討され,2018年(平成30年)著作権法改正により新設された法30条の4が導入され,47条の4,47条の5が新設された。この動きについてはブログで紹介している。(2022-12-08「Google Booksと同じような検索ツールは誰でもつくれる」)2021年法改正はこうした動きを受けてのものである。個人的には,2009年の31条6項がもっとも印象深い。NDLが入手した資料をすべてデジタル化することを可能とする規定だからである。
さて,こうした動きをどのように評価すべきだろうか。著作権を一部制限してデジタル化やデジタル資料の公衆送信を行うことはどのようにオープンサイエンスに近づくのだろうか。利用をパブリック・ドメインにおいたり,オープンライセンスを付与して利用しやすくすることは著作者や研究者などの発信者の役割であるのに対して,図書館は仲介者として,開かれたアクセスや直ちに又は可能な限り速やかに提供とか無償であることに貢献する。

かつては,こうした仲介者の役割はそれほど注目されなかったが,状況は大きく変化している。これは今まで述べたもの以外にも,デジタルアーカイブを横につなぐハブとなるJapan Searchの開発や先進的な知識工学的技術開発を行っているNDLラボなどの活動がある。国のデジタル化戦略に組み込まれていることは,たとえば,首相官邸に置かれた知的財産戦略本部が毎年出している『知的財産推進計画2024』では,NDLについて,「国立国会図書館は立法府に属する機関であるが、デジタルアーカイブに関する施策は国全体として取り組むものであり、同館は重要な役割を担っていることから、便宜上、本計画に関連する同館の事業について担当欄に記載するものである。」(p.64)と注記を入れて,何度も言及している。
この点で,NDLは(デジタル)コンテンツ保存・管理・発信のナショナルな専門機関としての役割を担う代表的な機関となっていることは明らかである。著作権を制限することで,知のオープン化に向けての仕掛けをすることに、国全体の合意が得られているのである。
別の観点から見ておくと,その陣容の大きさということがある。この点は図書館関係者はあまり口にしないが,スライドの<参考>にあるように,常勤職員の数が900人弱というのは,国内の大規模図書館のなかでもひときわ大きな存在である。このリストで横浜市や大阪市,東京大学は多数の地域館や部局図書館(室)を合わせての数である。また,文部科学省が外局や所轄機関を合わせて2000人程度の職員数であり,その半分くらいの規模があると考えてよい。こういう陣容の組織に,新しい時代のナショナルライブラリーの形を示してもらいたいと思うのは自然なことではないだろうか。

NDLのカバー範囲
次にオープンサイエンス知識の管理という図書館が貢献できる領域で,NDLがどのように位置付けられるのかについて見ておこう。次の図は縦軸にメディアのオープンネスの段階を4つに分け,横軸にはメディア発生の場と拡がりを4つに分けて示したものである。オープンネスは外部に対する公開の度合いであり,「クローズド」「グレイ」「パブリッシュ」「オープン」の4段階で示した。メディア発生の場と拡がりは,「プライベート」「コミュニティ・アソシエーション」「ナショナル」「インターナショナル」の4つである。これで,4×4=16のマトリックスができることになる。たとえば,「プライベート」なドキュメントとして,作家の書簡,日記,メモなどがあるが,通常は「クローズド」の形でつくられている。これが,何らかのかたちで「発見」され,研究対象になったりすれば「グレイ」の状態に置かれる。そして,それが公開すべきとなったときに,編集されたのちに著作集とか全集という形で「パブリッシュ」される。さらに,これがデジタル化されて「オープン」になる状態がある。「コミュニティ・アソシエーション」は中間段階の組織がもつドキュメントであり,「ナショナル」は国および国レベルでのドキュメントであり,「インターナショナル」は国を超えたレベルでのドキュメントでいずれも「クローズド」から「オープン」になる段階がある。

国立国会図書館の伝統的な守備範囲を見ると,本来納本制度は日本国内の「出版物」を対象としていたから,プライベートなものは除かれるとしても,国内出版のものはすべて含まれるはずである。その出版物の定義も映画フィルムやレコード盤,電子的・磁気的な記録物も含んだかなり広義のものだったが,ここでは主として文字を用いて知識を記録した「図書」「小冊子」「逐次刊行物」を考える。この図で網掛けで示したところは従来の納本制度がカバー範囲として想定してきた部分であり,「ナショナル」なレベルでの「パブリッシュ」されたものを中心としてきた。
なお,この図は大雑把なものしか示していない。「プライベート」なものでも「パブリッシュ」されれば納本対象になるはずだがそれらはここでは除かれている。これにインターネット資料やオンライン資料を含めて,現在の守備範囲は次のように示せるだろう。
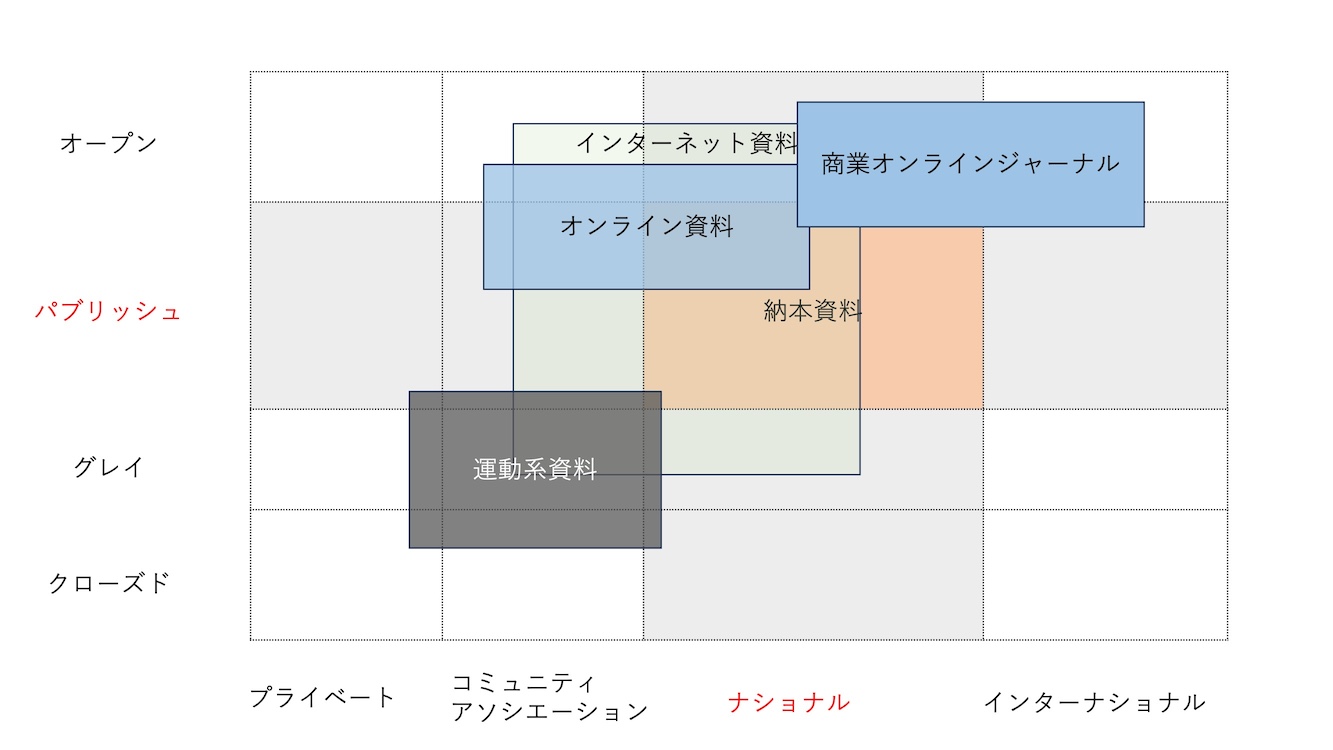
納本資料の中心である「ナショナル」×「パブリッシュ」の部分(オレンジ色)に加えて,グレーの部分は本来想定されているところかもしれない。「パブリッシュ」については「プライベート」から「インターナショナル」まで全部をカバーするはずである。薄緑色のインターネット資料は「コミュニティ・アソシエーション」の「グレイ」から「オープン」まで拡げてカバーすることができるし,青色のオンライン資料も「コミュニティ・アソシエーション」のカバーを拡げてくれる。
ここで「商業オンラインジャーナル」(青色)について,とくに外国のジャーナルは日本の法制度の適用外とされるからNDLではうまく対応できない。また「運動系資料」(黒)としているものは,「プライベート」や「コミュニティ・アソシエーション」の「クローズド」や「グレイ」のものを含むが,これらも一部を除くと対応できていない。

網羅と質の保証の両立は可能か?
以上のものを基にして,オープンサイエンス時代のNDLの資料保存と提供体制について考えてみたい。
・グレイな領域(地域資料,サブカル関係,運動系資料…)ーこれまでの図書館経営は学術資料を前提としてきたが,オープンサイエンスの理念の下にシティズン・サイエンスを考えると市民が直接生産したり,やりとりしたりするコンテンツの扱いが重要になる。これまでも地域資料やサブカル系資料,運動系資料は入手しにくくNDLは十分に対応してこなかったが,そのままでよいのか。
・クローズドな領域の受け皿(憲政資料室ほかの特別コレクションの拡大...)ーNDLの憲政資料室はクローズドな政治家の資料の受け皿として重要だった。国立公文書館他のアーカイブズ機関との関係をどのように考えるか。
・ネット上の無数のコンテンツの扱い(ブログ,オンライン文芸,オンラインジャーナリズム,写真,動画,ゲーム,データベース)ー出版物やオンライン資料の定義は実は曖昧であり,ネット上にさまざまなコンテンツがある。これらの一部はかつてなら紙の出版物として発行されたものがネット上に置きかわったものである(オンラインジャーナリズムなど)。動画やゲームのなかには十分な科学的根拠をもったコンテンツとして位置付けられるべきものも含まれる。
・動的に変化するコンテンツの保存問題(WARPの拡張,米Internet Archiveの苦闘)ーオンライン資料やインターネット資料は固定されたコンテンツにならず,常に変化する可能性がある。これは,「版」の概念とも「逐次刊行物」の概念で扱いきれないところがある。インターネット資料の検索システムをどのように考えるか。アメリカのInternet Archiveはフェアユースの範囲でコンテンツの公開を行っていたが,著作権者からの訴訟に悩まされている。NDLは法的な武装をしながらここまでやってきたわけだが,今後は著作権者や著作者との軋轢が生じる可能性もある。
ナショナルライブラリーは国民国家成立とともにつくられたが,その第一の目的は,国家にある知的所産を収集保存しそれを一望の下におくことで,知識の流通をはかることにあったと考えられる。ただし,それは書物などの紙メディアが知の流通と保存のためのメディアとして重要であると考えられたからである。NDLの成立の理念もそこにあるが,21世紀になってその前提は揺らいでいる。そもそも,納本制度で規定された資料のカテゴリーは古めかしく,それらを網羅的に集める意義は薄らぎつつある。とは言え,ネット上のものについてどのように網をかけて収集することができるのかについても不明の点が多い。













